


Leitura de placas de veículos: passado, presente e (muito) futuro
A leitura automática de placas veiculares (License Plate Recognition, LPR) é uma tecnologia que consiste em obter dados relacionados com a placa de um veículo utilizando uma imagem ou um grupo de imagens. Nos últimos anos, o reconhecimento de placas de veículos tem sido um campo de visualização computadorizada (Computer Vision, CV) amplamente utilizado em diferentes setores relacionados à vigilância veicular: segurança rodoviária, controle de acesso a estacionamentos ou sistemas automáticos de cobrança de pedágio e sistemas de estacionamento, entre muitos outros.
Como e quando surge a necessidade do leitor de placas de veículos?
As primeiras referências existentes a uma LPR datam de 1976, quando a “Police Scientific Development Branch” do Reino Unido implementou o primeiro sistema, que começou a funcionar em 1979. Além de ser um desafio técnico, uma situação com a qual os pesquisadores costumam lidar, o objetivo desta aplicação foi claro desde o princípio: aumentar a segurança. A partir de então, houve uma grande evolução tanto nos aspectos técnicos quanto nos campos de aplicação.
Qual tem sido a evolução da tecnologia de identificação de placas de veículos ao longo do tempo?
No início, esses sistemas estavam formados por duas partes claramente diferenciadas: a primeira era a ótica, com câmeras otimizadas para captar bem a imagem; e o segundo consistia em uma CPU externa com poder computacional suficiente para processar o reconhecimento ótico de caracteres (Optical Character Recognition, OCR), em um tempo razoável. Embora este primeiro modelo ainda possa continuar sendo válido, a evolução das CPUs para componentes cada vez menores, mais potentes e mais baratos, fez com que os sistemas evoluíssem para dispositivos do tipo All-in-One, ganhando muito mais versatilidade.
É fato que, nos últimos anos, o mundo da inteligência artificial (Artificial Intelligence, AI) tem revolucionado o mundo da programação. Embora a AI possa parecer um conceito muito novo, suas primeiras referências datam dos anos 50. Em 1956, durante a conferência de Dartmouth, um pequeno grupo de profissionais de diferentes áreas se reuniu para concentrar sua atenção no mundo iniciante dos computadores e em sua capacidade potencial de manifestar um comportamento inteligente.
Desde então, este campo tem progredido muito e, na última década, uma nova tecnologia tem revolucionado o mundo da IA: o aprendizado profundo (Deep Learning, DL). Esta metodologia é um ramo do Machine Learning ou aprendizado de máquina que consiste em aprender através do exemplo. É criado um modelo capaz de avaliar exemplos e uma pequena coleção de instruções para modificar este modelo quando ocorrem erros. O objetivo é que o sistema consiga aprender com sua própria experiência de forma autônoma e que, durante o processo de treinamento e aprendizagem, seja capaz de identificar padrões que lhe permitam resolver um problema complexo de forma extremamente precisa. Uma das técnicas mais comuns de implementação do DL é utilizando redes neurais.
Mas o que são redes neurais e como elas funcionam?
As redes neurais artificiais são um modelo inspirado no funcionamento do cérebro humano. Essas redes são formadas por um conjunto de nós conhecidos como neurônios artificiais, que são agrupados em camadas, criando assim uma rede neural. Os nós estão conectados uns aos outros para que um input possa ser transmitido até gerar um output. Cada neurônio tem um peso, que nada mais é do que um valor numérico que modifica o input recebido. Os novos valores gerados saem dos neurônios e continuam seu caminho através da rede, obtendo um output que será a previsão calculada da rede. Quanto mais camadas houverem, mais complexa será a rede e, por sua vez, mais complexos serão os problemas que ela será capaz de resolver.
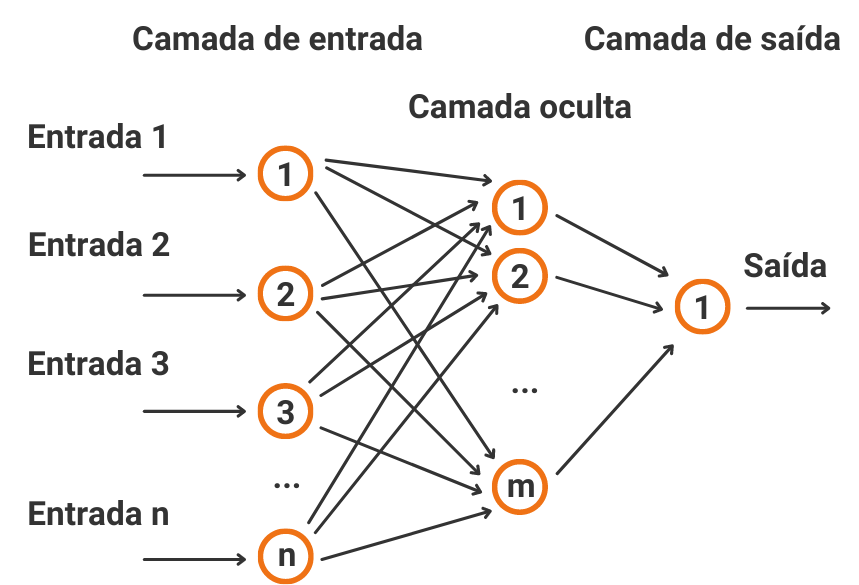
O principal objetivo deste modelo é que ele seja capaz de se modificar a si mesmo para poder realizar tarefas complexas que não poderiam ser programadas utilizando a programação clássica baseada em regras. Este procedimento é realizado durante o processo de treinamento, durante o qual os dados são introduzidos no input e, em função do resultado obtido, os pesos dos neurônios são modificados de acordo com o erro identificado. Este método é conhecido como “Backpropagation”. Desta forma, a rede vai aprendendo automaticamente até obter os resultados desejados, conseguindo que sejam muito exatos e precisos.
O Deep Learning aplicado à tecnologia de leitura de placas
Para nós, que nos dedicamos à pesquisa e desenvolvimento no campo da identificação de placas de veículos, existem muitos desafios que temos de enfrentar para conseguir que o processo de leitura seja eficaz. Neste sentido, o sistema precisa ser rápido e eficaz em diferentes condições de captura de imagem: condições de iluminação (dia ou noite), posição e especificações da câmera (ângulo, perspectiva, distância ou resolução). Por outro lado, a grande variedade de tipologias de placas veiculares, que utilizam diferentes cores, fontes e alfabetos, tornam a leitura de placas um desafio técnico complexo e bastante estimulante.
Nos últimos tempos, o ramo do conhecimento envolvido com o DL está a todo vapor graças a seu potencial de aplicação ao mundo do Big Data e da Internet das Coisas (IoT). Toda essa evolução também está sendo aplicada ao mundo da LPR para fazer o que sempre temos feito: melhorar e procurar novas possibilidades de aperfeiçoamento. Além disso, é preciso considerar que as técnicas clássicas de CV já atingiram seus patamares técnicos e não estão entre as tecnologias de ponta, pelo menos em cenários não controlados, dado que nenhuma regra pode ser programada para lidar com as infinitas combinações de dados de input que ocorrem no mundo real.
Assim sendo, se nós transformarmos cada etapa do processo de identificação de placas em um problema de otimização com uma complexa distribuição de erros, podemos nos beneficiar do DL e atingir taxas de acerto muito altas. Porém, tudo isso requer uma quantidade diferente de memória e tempo de processamento dos que tínhamos utilizado até agora. Por este motivo, são utilizadas unidades de processamento especiais, tais como unidades de processamento gráfico (Graphics Processing Units, GPUs) ou unidades de processamento neural (Neural Processing Units, NPUs) para obter tempos de resposta eficientes em modelos mais ou menos complexos.
A mesma história se repete
No momento atual, estamos em um ponto de inflexão semelhante ao que estávamos anos atrás com as CPUs: a tecnologia não é barata o suficiente para ser usada em grande escala. Isto abre a porta para duas possibilidades principais: Assumirmos o desafio de um sistema integrado All-in-One, onde a evolução do hardware ainda tem (razoavelmente) um longo caminho a percorrer, ou romper com a filosofia All-in-One optando pelo processamento de DL em um servidor externo (ou nuvem). A tecnologia evolui de forma muito rápida e o que hoje é inviável por razões de custo pode se tornar totalmente acessível em poucos meses. O futuro está cheio de possibilidades e todas elas melhoram, com certeza, a qualidade geral e a eficiência de nossos sistemas LPR.
Um futuro que promete
Em conclusão, a tecnologia LPR está muito longe de ficar estagnada. O surgimento do DL está trazendo um novo impulso que nos permite atingir taxas de sucesso extremamente elevadas, fazendo com que sejamos capzes de resolver situações complexas de uma maneira muito mais fluida e rápida do que no passado. É um bom momento para continuar investindo em pesquisa nessa área e, na Quercus Technologies, queremos continuar trilhando este caminho com o objetivo de fornecer sempre as melhores soluções de estacionamento para nossos clientes e ajudá-los a resolver seus problemas.
R&D Computer Vision Team Responsible na Quercus Technologies

Entre em contato conosco
Se você está procurando respostas, quer obter mais informações, deseja resolver um problema ou simplesmente quer comentar sobre nosso trabalho, entre em contato conosco.
Ficamos felizes em poder ajudá-lo!